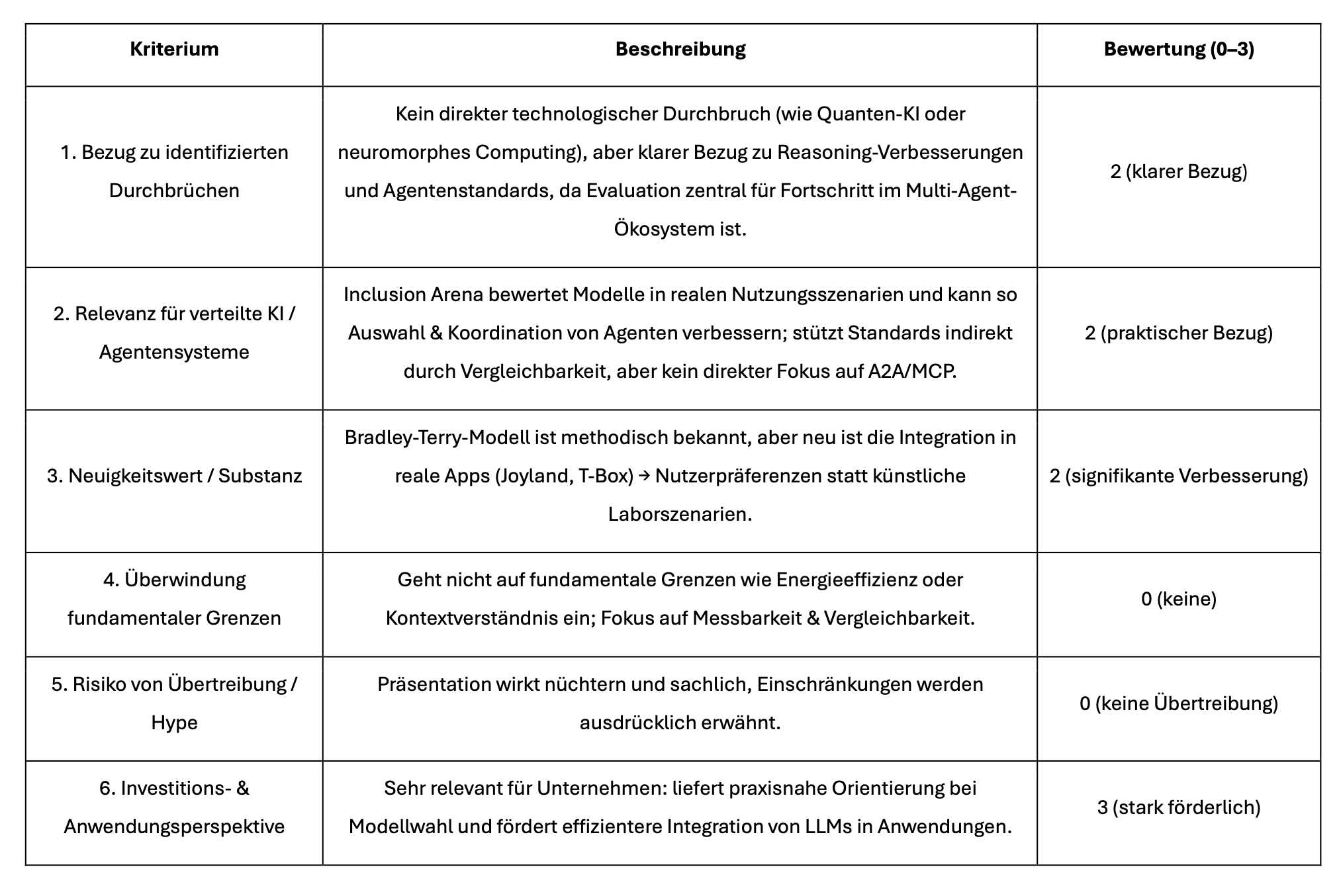
Forscher von Inclusion AI, einer Alibaba Ant Group-Tochter, schlagen mit Inclusion Arena ein neues Benchmark- und Leaderboard-System vor, das sich auf reale Nutzungsszenarien und Nutzerpräferenzen konzentriert. Im Gegensatz zu herkömmlichen Methoden wie MMLU oder OpenLLM werden Modelle bei Inclusion Arena in realen Anwendungen getestet, wobei Nutzerantworten anonym bewertet werden1Stop benchmarking in the lab: Inclusion Arena shows how LLMs perform in production.
Das System basiert auf dem Bradley-Terry-Modell, das stabilere Bewertungen als das häufig verwendete Elo-Rating liefert. Da umfassende Modellvergleiche ressourcenintensiv sind, bietet Inclusion Arena Mechanismen wie Placement Matches für neue Modelle und Proximity Sampling, um Vergleiche auf relevante Modelle zu beschränken.
Funktionsweise
- Integration in Apps: Inclusion Arena ist in Apps wie Joyland (Chat-App) und T‑Box (Bildungs-App) integriert.
- Nutzerbewertungen: Nutzer wählen die beste Antwort, ohne zu wissen, welches Modell sie generiert hat.
- Ranking: Die Bewertungen fließen in das Bradley-Terry-Modell ein, um ein Leaderboard zu erstellen.
Ergebnisse und Ziele
- Erste Experimente mit 501.003 Vergleichsdaten aus zwei Apps zeigen, dass Anthropic’s Claude 3.7 die beste Leistung bietet.
- Mit mehr Daten und Anwendungen soll das System präziser und umfassender werden.
Bedeutung
Inclusion Arena bietet Unternehmen eine praxisnahe Orientierungshilfe bei der Auswahl von LLMs, indem es Modelle nach realer Leistung statt rein theoretischen Tests bewertet. Damit ergänzt es die wachsende Anzahl an Benchmarks, die reale Anwendungsfälle betonen, wie z. B. RewardBench 2.
Unternehmen sollten jedoch weiterhin interne Tests durchführen, um sicherzustellen, dass Modelle für ihre spezifischen Anforderungen geeignet sind.
Das Bradley-Terry-Modell ist ein statistisches Modell, das verwendet wird, um die Wahrscheinlichkeit vorherzusagen, dass eine von zwei Alternativen (z. B. Spieler, Teams oder Modelle) in einem Paarvergleich gewinnt. Es basiert auf der Annahme, dass jede Alternative eine inhärente “Stärke” oder Fähigkeit besitzt, die ihre Gewinnwahrscheinlichkeit bestimmt.
Funktionsweise
- Jede Alternative (z. B. ein Modell) wird durch einen Parameter dargestellt, der ihre latente Fähigkeit oder Stärke beschreibt.
- Die Wahrscheinlichkeit, dass Alternative A gegen Alternative B gewinnt, wird durch die folgende Formel berechnet: P(A gewinnt gegen B) = s(A) / (s(A) + s(B)) Hierbei ist:
- s(A): die Stärke von Alternative A,
- s(B): die Stärke von Alternative B.
- Das Modell basiert auf Paarvergleichen, wobei die Ergebnisse genutzt werden, um die Stärken der Alternativen zu schätzen.
Eigenschaften
- Das Modell ist ein paarweises Vergleichsmodell, das besonders in Szenarien eingesetzt wird, in denen es schwierig ist, eine absolute Bewertung zu geben.
- Es liefert wahrscheinlichkeitsbasierte Bewertungen und erlaubt es, die Rangfolge von Alternativen auf Basis der relativen Stärke zu bestimmen.
- Die Berechnungen erfolgen oft durch Maximum-Likelihood-Schätzungen, um die Modellparameter zu optimieren.
Einsatzgebiete
- Sport: Bewertung von Teams oder Spielern (z. B. in Schachturnieren).
- Maschinelles Lernen: Vergleich von KI-Modellen (z. B. in Inclusion Arena oder Chatbot Arena).
- Psychologie: Untersuchung von Präferenzen bei Experimenten.
- Recommender-Systeme: Bewertung von Produkten oder Diensten basierend auf Nutzerpräferenzen.
Vorteile des Bradley-Terry-Modells
- Stabilität: Es liefert robuste Rankings, insbesondere bei inkonsistenten oder unvollständigen Vergleichsdaten.
- Flexibilität: Kann auf verschiedene Arten von Vergleichsdaten angewendet werden.
- Wachstumsfähigkeit: Es ist skalierbar und kann an große Datensätze angepasst werden.
Einschränkungen
- Bei einer großen Anzahl von Alternativen können exhaustive Paarvergleiche (d. h. alle möglichen Kombinationen) schnell ressourcenintensiv werden.
- Die Annahme, dass sich die Stärke einer Alternative nicht ändert, ist in dynamischen Umgebungen möglicherweise nicht immer realistisch.
In Systemen wie Inclusion Arena wird das Bradley-Terry-Modell verwendet, um die Stärke verschiedener KI-Modelle basierend auf Nutzerpräferenzen zu vergleichen und ein stabiles Ranking zu erstellen.
Bewertung nach dem KI-Agenten — Framework