
Eine Studie der Arizona State University entlarvt das „Chain-of-Thought”-Denken in Large Language Models als anspruchsvoll gemusterte Imitation echter Intelligenz. Die Ergebnisse werfen fundamentale Fragen über die Grenzen heutiger KI-Systeme auf und fordern einen grundlegend vorsichtigeren Umgang mit vermeintlich „denkenden” Algorithmen.
Die große Illusion des maschinellen Denkens
Was unterscheidet echtes Denken von brillant nachgeahmtem Verstehen? Diese philosophische Frage erhält durch eine neue Studie der Arizona State University eine überraschend konkrete Antwort. Forscher haben das sogenannte „Chain-of-Thought” (CoT)-Reasoning in Large Language Models unter die Lupe genommen und dabei eine ernüchternde Entdeckung gemacht: Was wir für intelligentes Schlussfolgern halten, entpuppt sich als ein „fragiles Trugbild” – ein ausgeklügeltes System des Musterabgleichs, das bei der ersten unvorhergesehenen Wendung versagt1LLMs generate ‘fluent nonsense’ when reasoning outside their training zone.
Wenn die Maske fällt: Die Grenzen der Generalisierung
Die Studie offenbart ein fundamentales Problem moderner KI-Systeme: ihre erschreckend begrenzte Fähigkeit zur Generalisierung. Chain-of-Thought-Prompting funktioniert nur solange zuverlässig, wie die Testdaten strukturell den Trainingsdaten ähneln. Sobald jedoch neue Aufgabentypen, veränderte Argumentationskettenlängen oder modifizierte Prompt-Formate ins Spiel kommen, bricht die vermeintliche Denkleistung zusammen wie ein Kartenhaus.
Diese Erkenntnisse stellen die weit verbreitete Annahme in Frage, dass CoT-Reasoning ein Durchbruch hin zu abstraktem maschinellem Denken darstellt. Stattdessen zeigt sich, dass diese Systeme lediglich hochentwickelte Mustererkenner sind – brillant darin, bekannte Strukturen zu reproduzieren, aber hilflos, wenn sie mit wirklich neuen Herausforderungen konfrontiert werden.
Musterabgleich als falscher Messias
Die Mechanik hinter dem vermeintlichen „Denken” entlarvt sich als ernüchternd simpel: Anstatt logische Schlussfolgerungen zu ziehen, rekonstruieren die Modelle lediglich Muster aus ihren Trainingsdaten. Diese Erkenntnis ist nicht nur akademisch relevant, sondern hat weitreichende praktische Implikationen. In „Out-of-Distribution”-Situationen – also bei Daten oder Aufgaben, die vom Trainingsbereich abweichen – versagen diese Systeme systematisch.
Besonders problematisch ist dabei das Phänomen des „Fluent Nonsense”: Die Modelle produzieren Antworten, die sprachlich elegant und inhaltlich plausibel wirken, tatsächlich aber grundlegende logische Fehler enthalten. Diese scheinbare Kompetenz kann gefährlich irreführend sein, insbesondere wenn Nutzer den erzeugten Inhalten blind vertrauen.
Fine-Tuning: Pflaster auf einer Wunde
Die Forscher identifizierten Fine-Tuning als potenzielle Lösungsstrategie – jedoch mit erheblichen Einschränkungen. Durch gezieltes Nachtraining lässt sich die Leistung für spezifische Aufgaben durchaus verbessern. Doch dies löst das Kernproblem nicht, sondern erweitert lediglich den Bereich der „In-Distribution”-Daten. Die fundamentale Schwäche des Systems – die Unfähigkeit zu echter Abstraktion und Generalisierung – bleibt bestehen.
Praktische Konsequenzen für die KI-Entwicklung
Die Studienergebnisse haben unmittelbare Auswirkungen auf die Entwicklung und den Einsatz von LLM-basierten Anwendungen. Entwickler und Unternehmen sollten drei zentrale Lektionen beherzigen:
- Erstens: Übermäßiges Vertrauen in CoT-Reasoning ist fehl am Platz, insbesondere in kritischen Anwendungsbereichen wie Finanzen, Recht oder Medizin. Die Gefahr des „Fluent Nonsense” macht fachliche Überprüfungen unverzichtbar.
- Zweitens: Rigoroses Out-of-Distribution-Testing sollte zum Standard werden. Systematische Tests mit ungewohnten Aufgaben, verschiedenen Prompt-Längen und modifizierten Formaten können aufdecken, wo die Grenzen des Systems liegen.
- Drittens: Fine-Tuning sollte als chirurgisches Instrument verstanden werden, nicht als Allheilmittel. Es kann spezifische Schwächen adressieren, aber nicht die grundlegenden architekturellen Limitierungen überwinden.
Der Weg nach vorn: Ehrlichkeit statt Hype
Die ASU-Studie liefert einen wertvollen Realitätscheck in einer Zeit, in der KI-Fähigkeiten oft überschätzt werden. Sie zeigt, dass Chain-of-Thought-Reasoning durchaus nützlich sein kann – aber nur innerhalb klar definierter Grenzen und mit angemessenen Sicherheitsvorkehrungen.
Für die Zukunft der KI-Entwicklung bedeutet dies: Weniger Hype, mehr Präzision. Anstatt universelle Denkmaschinen zu postulieren, sollten wir uns darauf konzentrieren, spezialisierte Systeme zu entwickeln, die in abgegrenzten Bereichen zuverlässig funktionieren. Die Studie bietet dafür einen praktischen Rahmen – eine Roadmap für die Entwicklung robuster LLM-Anwendungen, die ihre Grenzen kennen und respektieren.
Die Erkenntnis, dass aktuelles Chain-of-Thought-Reasoning ein „fragiles Trugbild” ist, mag ernüchternd wirken. Doch sie eröffnet auch die Chance für eine reifere, verantwortungsvollere Entwicklung künstlicher Intelligenz – eine, die auf Realismus statt auf Illusionen baut.
Bewertung mit dem KI-Agenten — Framework
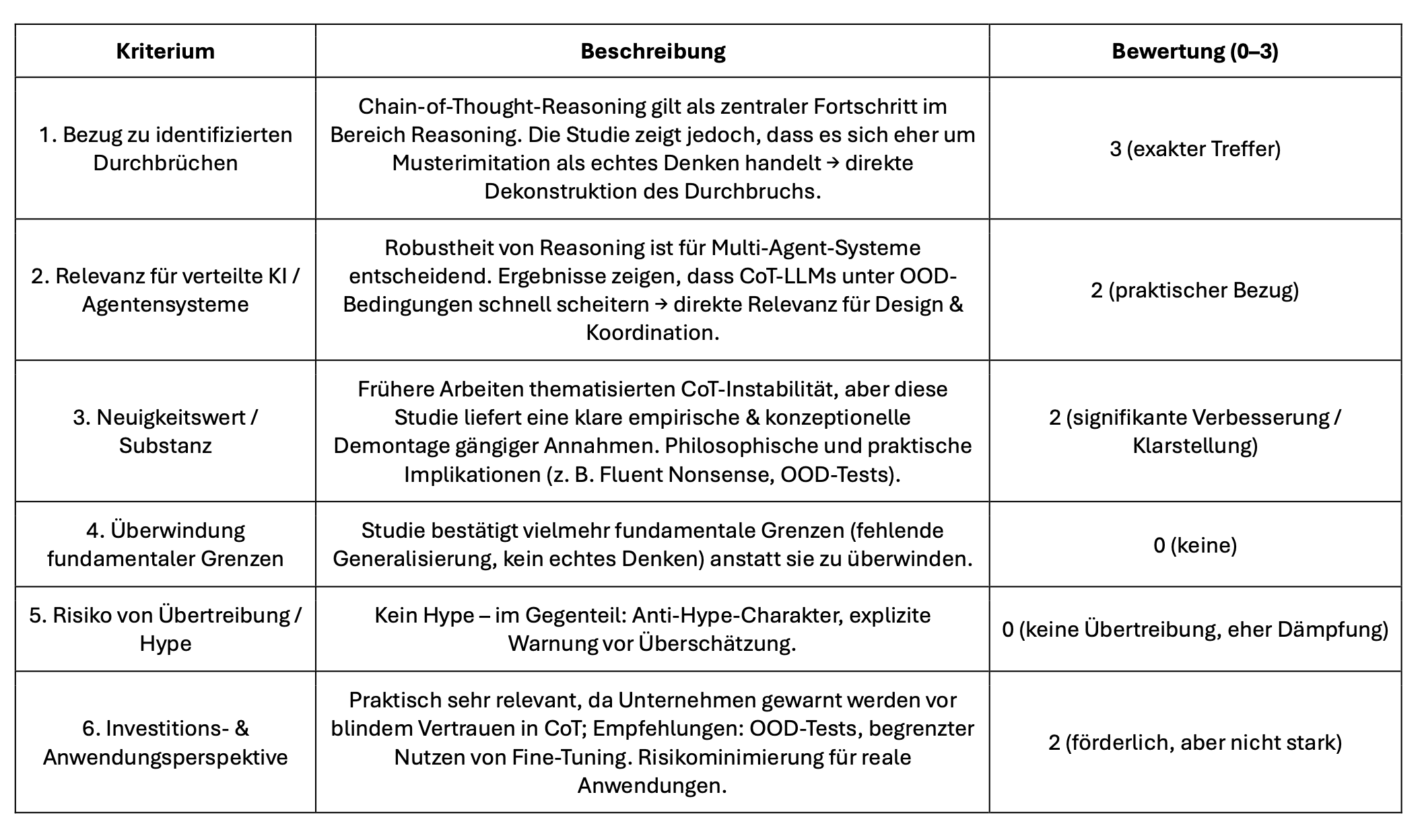
Die Studie ist kein Durchbruch im üblichen Sinn, sondern eine kritische Dekonstruktion eines der meistdiskutierten Fortschrittsfelder (Chain-of-Thought). Sie ist zugleich Anti-Hype und Handlungsorientierung: Für Forschung und Anwendungen liefert sie zentrale Einsichten, wie begrenzt CoT-basiertes Reasoning tatsächlich ist.