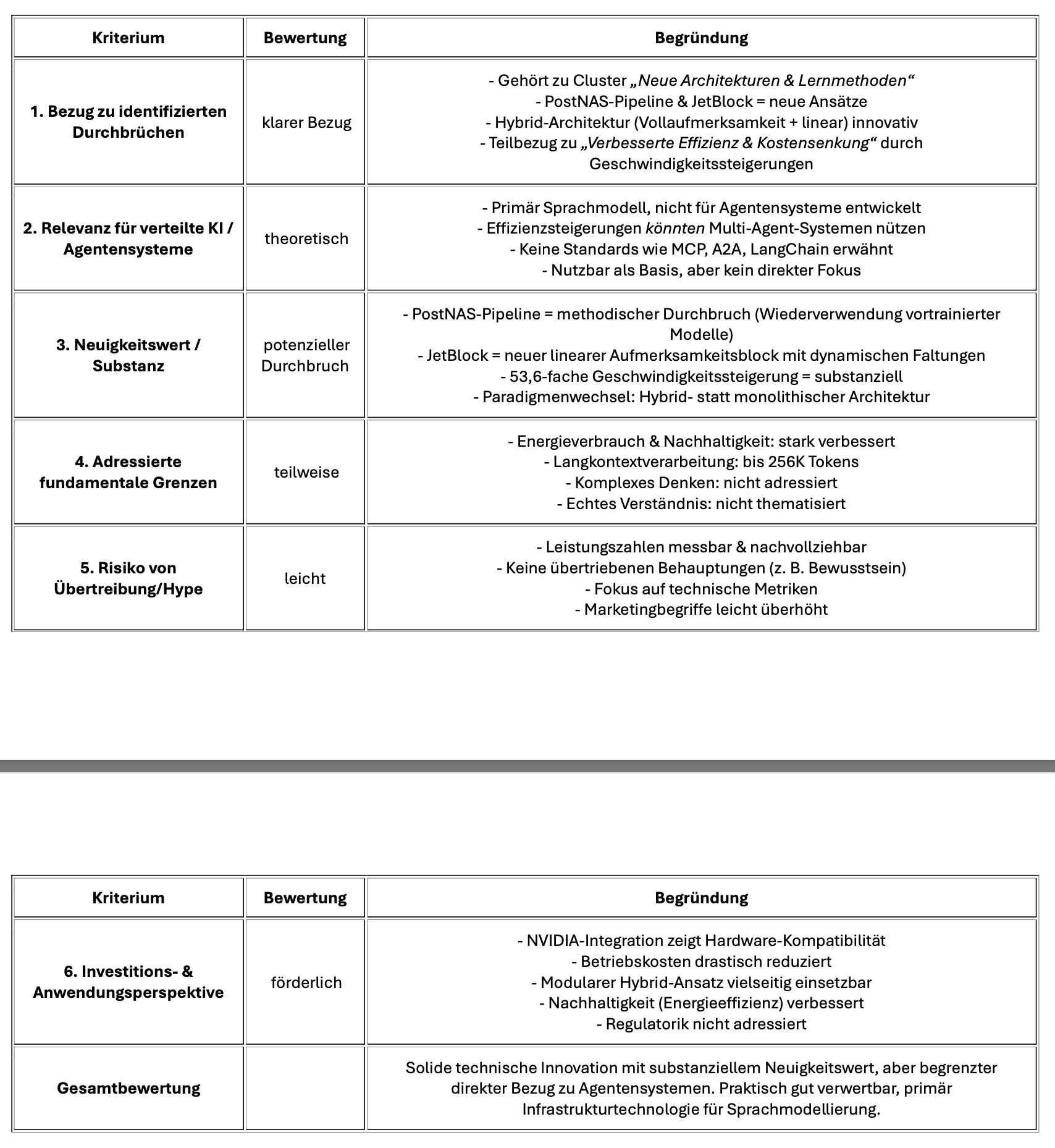
Forscher von NVIDIA haben mit Jet-Nemotron einen methodischen Ansatz entwickelt, der das Effizienz-Genauigkeits-Problem in Sprachmodellen durch eine Post Neural Architecture Search-Pipeline adressiert. Die Ergebnisse zeigen bis zu 53-fache Geschwindigkeitsverbesserungen bei vergleichbarer Präzision – ein bemerkenswerter Fortschritt in der Optimierung von KI-Architekturen.
Das anhaltende Optimierungsproblem
Die Entwicklung von Sprachmodellen steht seit Jahren vor einem grundlegenden Zielkonflikt: Modelle mit Vollaufmerksamkeit bieten hohe Genauigkeit, benötigen aber erhebliche Rechenressourcen. Effizientere Alternativen erreichen oft nicht die gleiche Präzision. Diese Konstellation erschwert die breite Anwendung fortschrittlicher Sprachmodelle und führt zu hohen Betriebskosten. Eine aktuelle Forschungsarbeit von NVIDIA untersucht neue Wege zur Lösung dieses Problems.
Post Neural Architecture Search: Methodische Weiterentwicklung
Der zentrale Beitrag liegt in der Post Neural Architecture Search (PostNAS)-Pipeline, die einen systematischen Ansatz zur Architekturentwicklung verfolgt. Anstatt neue Modelle von Grund auf zu trainieren, verwendet PostNAS bereits vortrainierte Vollaufmerksamkeitsmodelle als Ausgangsbasis. Diese Methodik reduziert sowohl die Kosten als auch das Risiko bei der Architektursuche erheblich.
Die Pipeline konzentriert sich auf vier wesentliche Komponenten: die strategische Platzierung und Entfernung von Vollaufmerksamkeits-Layern, die Auswahl geeigneter linearer Aufmerksamkeitsblöcke, die Entwicklung neuer Aufmerksamkeitsstrukturen und eine hardware-orientierte Hyperparameteroptimierung. Dabei werden die Gewichte des Multi-Layer Perceptrons eingefroren, was den Suchprozess fokussiert und beschleunigt.
JetBlock: Technische Innovation
Ein wesentliches Element der Entwicklung ist der JetBlock, ein linearer Aufmerksamkeitsblock, der dynamische Faltungen mit linearer Aufmerksamkeit kombiniert. Diese Struktur zeigt Verbesserungen gegenüber bestehenden Ansätzen wie Gated DeltaNet sowohl bei der Effizienz als auch bei der Genauigkeit. Der JetBlock repräsentiert einen durchdachten Ansatz zur Integration verschiedener Aufmerksamkeitsmechanismen.
Empirische Ergebnisse
Die Leistungstests zeigen deutliche Verbesserungen in mehreren Dimensionen. Jet-Nemotron-2B erreicht eine bis zu 47-fache Beschleunigung gegenüber Qwen3‑1.7B-Base bei gleichzeitig höherer Genauigkeit in standardisierten Benchmarks wie MMLU-Pro und Retrieval-Aufgaben. Die größere Variante Jet-Nemotron-4B setzt diese Entwicklung fort und zeigt eine 21-fache Beschleunigung bei weiterhin verbesserter Genauigkeit.
Besonders ausgeprägt sind die Effizienzgewinne bei Langkontextaufgaben mit 256.000 Tokens, wo eine 53,6‑fache Beschleunigung gemessen wurde. Die Tests auf NVIDIA H100 GPUs dokumentieren signifikante Verbesserungen sowohl beim Prefilling als auch bei der Dekodierung.
Hybride Architekturansätze
Jet-Nemotron demonstriert die Praktikabilität hybrider Systeme, die Vollaufmerksamkeits- und lineare Aufmerksamkeitsblöcke strategisch kombinieren. Diese Herangehensweise ermöglicht es, die Vorteile beider Ansätze zu nutzen und gleichzeitig deren jeweilige Limitationen zu kompensieren. Die Ergebnisse deuten darauf hin, dass solche Hybridmodelle ein vielversprechender Entwicklungspfad sind.
Praktische Implikationen
Die PostNAS-Pipeline etabliert einen methodischen Ansatz zur Architekturentwicklung, der vortrainierte Modelle als Grundlage nutzt. Dies könnte zu effizienteren Entwicklungsprozessen und reduzierten Kosten bei der Erstellung neuer Modellarchitekturen führen.
Für praktische Anwendungen bedeutet dies erweiterte Möglichkeiten für den Einsatz fortschrittlicher Sprachmodelle in ressourcenbeschränkten Umgebungen. Von mobilen Anwendungen bis hin zu Edge-Computing-Szenarien ergeben sich neue Einsatzfelder für leistungsfähige KI-Systeme.
Einordnung und Ausblick
Jet-Nemotron stellt einen systematischen Fortschritt in der Optimierung von Sprachmodellen dar. Die Forschungsarbeit zeigt, dass methodische Ansätze zur Architekturentwicklung zu messbaren Verbesserungen in beiden kritischen Dimensionen – Effizienz und Genauigkeit – führen können.
Die Arbeit des Teams um Yuxian Gu dokumentiert einen strukturierten Weg zur Entwicklung optimierter Sprachmodelle. Mit der Kombination aus PostNAS-Pipeline, JetBlock-Innovation und hybriden Architekturen haben sie einen Ansatz entwickelt, der sowohl theoretisch fundiert als auch praktisch relevant ist. Die Ergebnisse legen nahe, dass ähnliche methodische Ansätze weitere Optimierungen in der Sprachmodellentwicklung ermöglichen könnten.
Bewertung mit dem KI-Agenten-Framework